Exploratory Analysis
So you come into work on a Monday morning and find that your boss has tasked you with finding some insights on a current data set. You open the excel file and see that there are countless rows and columns filled with data. What do you do next?
Well, because you are a trendy analyst or someone just looking to learn new skills, you decide to use Python.
In this short blog, I will teach you how to begin looking for insights into your data, or in other terms, exploratory analysis. We will use Python 3 and the libraries within Python to start our journey.
First off, you are going to import the Pandas library, Matplotlib library, and the Seaborn library.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
These are just a few of the libraries that are available for use within the Python language and in our case, will be the main libraries used for exploratory analysis.
Next, you will call your bosses saved excel file name that you would have saved as a CSV file.
example_1 = pd.read_csv('~/Documents/projects/project_1/data/act_2018.csv')
Now that you have loaded your file into the notebook, or text editor, you can begin the initial analysis with some Pandas functions.
Run the .head() function to show the first five rows, and all the column names to see what each is called - this will help when you start plotting later.
example_1.head()
| State | Participation | English | Math | Reading | Science | Composite | |
|---|---|---|---|---|---|---|---|
| 0 | National | 55 | 20.2 | 20.5 | 21.3 | 20.7 | 20.8 |
| 1 | Alabama | 100 | 18.9 | 18.3 | 19.6 | 19.0 | 19.1 |
| 2 | Alaska | 33 | 19.8 | 20.6 | 21.6 | 20.7 | 20.8 |
| 3 | Arizona | 66 | 18.2 | 19.4 | 19.5 | 19.2 | 19.2 |
| 4 | Arkansas | 100 | 19.1 | 18.9 | 19.7 | 19.4 | 19.4 |
Next, run the .tail() function to show the bottom of your DataFrame.
example_1.tail()
| State | Participation | English | Math | Reading | Science | Composite | |
|---|---|---|---|---|---|---|---|
| 47 | Virginia | 24 | 23.8 | 23.3 | 24.7 | 23.5 | 23.9 |
| 48 | Washington | 24 | 21.4 | 22.2 | 22.7 | 22.0 | 22.2 |
| 49 | West Virginia | 65 | 19.8 | 19.4 | 21.3 | 20.4 | 20.3 |
| 50 | Wisconsin | 100 | 19.8 | 20.3 | 20.6 | 20.8 | 20.5 |
| 51 | Wyoming | 100 | 19.0 | 19.7 | 20.6 | 20.3 | 20.0 |
Now that you have a basic understanding of your data, you should check to see if there are any null/zero values in your columns and what type of data is in your columns.
example_1.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 52 entries, 0 to 51
Data columns (total 7 columns):
State 52 non-null object
Participation 52 non-null int64
English 52 non-null float64
Math 52 non-null float64
Reading 52 non-null float64
Science 52 non-null float64
Composite 52 non-null float64
dtypes: float64(5), int64(1), object(1)
memory usage: 3.0+ KB
In this data set, you can see that there are no null values and that there is a mixture of object type data and float type data and int type data.
Next, you can use the .describe().T function to see things like min and max values in each column, as well as standard deviation and the mean in each column.
example_1.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Participation | 52.0 | 61.519231 | 33.757782 | 7.0 | 29.250 | 65.50 | 100.000 | 100.0 |
| English | 52.0 | 20.973077 | 2.424719 | 16.6 | 19.100 | 20.20 | 23.700 | 26.0 |
| Math | 52.0 | 21.113462 | 2.017573 | 17.8 | 19.400 | 20.65 | 23.125 | 25.2 |
| Reading | 52.0 | 22.001923 | 2.148186 | 18.0 | 20.475 | 21.45 | 24.050 | 26.1 |
| Science | 52.0 | 21.332692 | 1.853848 | 17.9 | 19.925 | 20.95 | 23.025 | 24.9 |
| Composite | 52.0 | 21.473077 | 2.087696 | 17.7 | 19.975 | 21.05 | 23.525 | 25.6 |
You can see with just a few simple functions from the Pandas library; we have gained a significant understanding of our numerical data.
And now, its time to bring in the next library, Matplotlib, which gives us the ability to start plotting some data.
Let's get started first by plotting each column in simple histograms. Maybe it will provide some insight into our data - like if it is normalized or not.
plt.figure(figsize=(4,4))
plt.hist(example_1['English']);

plt.figure(figsize=(4,4))
plt.hist(example_1['Math']);

plt.figure(figsize=(4,4))
plt.hist(example_1['Reading']);
plt.figure(figsize=(4,4))
plt.hist(example_1['Science']);
plt.figure(figsize=(4,4))
plt.hist(example_1['Composite']);
You can use Matplotlib to plot a few different styles of graphs quickly, but for exploratory, I like to keep things simple with either histograms or scatterplots because they visualize the data efficiently.
Remember, when doing exploratory analysis, you don't need to make things pretty, you need to make things easy for you to read and understand.
The last visual image I like to use is a heatmap; it shows correlation among our numerical columns, cleanly and effectively. This is where we use Seaborn.
fig, ax = plt.subplots(figsize=(6,6))
sns.heatmap(example_1.corr(), annot=True, cmap="icefire");
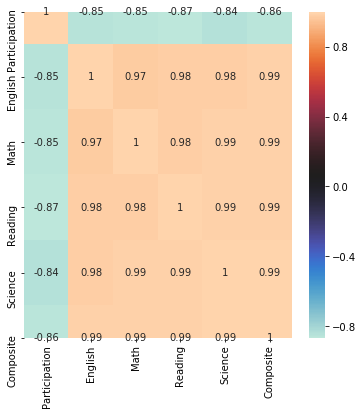
You can see the value of the heatmap right away. The human eye interprets colour coordination quickly and effectively. Using the "icefire" colorway, you can see that Participation is negatively correlated with all of the scores provided by the ACT. A powerful insight that you maybe wouldn't have noticed without the power of a heatmap.
And that's it. In less than 20 minutes, expert or not in Python, you can quickly explore your data and see what trends and interpretations you can make. You can now report back to your boss what you are seeing, or if you feel like you'd want to go further, check back soon for the next blog!